30 Tage Zufriedenheitsgarantie oder Geld-zurück
Rat : +33 257 880 074
 de
de 









Komplette software
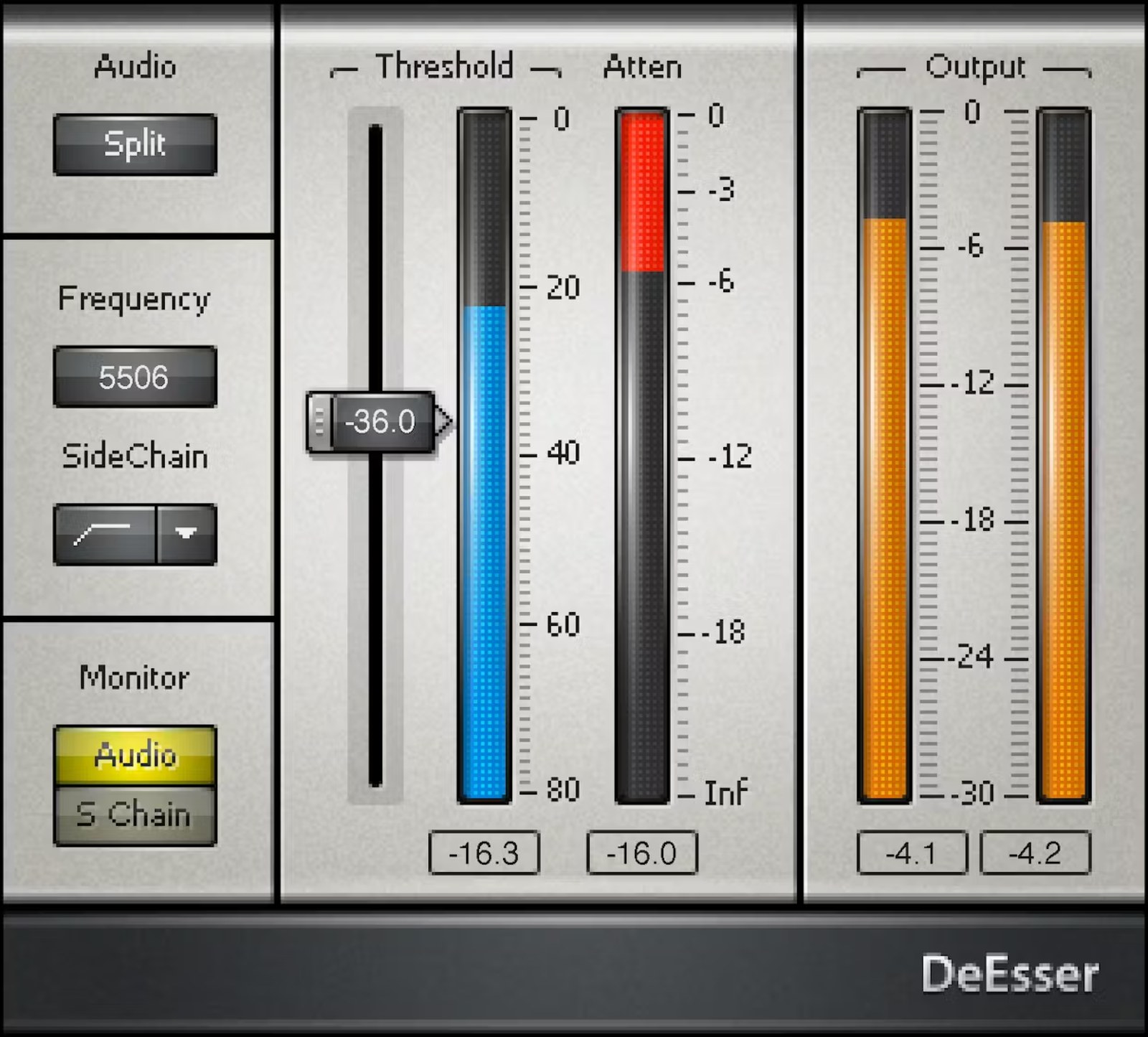
Waves DeEsser ist ein dynamisches Effekt-Plugin, das entwickelt wurde, um Zischlaute und Aggressivität hoher Frequenzen in einem Audiosignal zu reduzieren. Es richtet sich in erster Linie an Sprachproduktionen (Gesang, Voice-over, Podcast, Hörbuch, Erzählung), bei denen die Verständlichkeit verbessert werden soll, ohne dass die Konsonanten "s" und "sch" nach Equalizing oder Kompression zu dominant werden. Dank seiner progressiven Wirkung eignet es sich auch sehr gut, um quellreiche Transienten wie Becken, Drumloops oder die manchmal harte Brillanz bestimmter Synthesizer und digitaler Bearbeitungen abzumildern.
Um sich an sehr unterschiedliche Stimmen und Aufnahmen anzupassen, bietet DeEsser zwei Sidechain-Modi. Der Highpass-Modus arbeitet auf einem breiten Bereich, um die aufdringlichsten Zischlaute über ein weites Spektrum zu reduzieren, ideal wenn die "s"-Laute je nach Wort stark variieren. Der Bandpass-Modus ermöglicht hingegen, einen engeren problematischen Bereich zu fixieren, um genau die Frequenz zu treffen, die die Aggressivität auslöst.
Der Workflow ist bewusst direkt: Man wählt den zu bearbeitenden Bereich (von 2 kHz bis 16 kHz) und passt dann den Threshold an, um die Reduktion zu dosieren. Das Plugin basiert auf einer Hard-Knee-Kompressionslogik, was die Erzielung eines klaren und kontrollierbaren Ergebnisses erleichtert. Das Reduktions-VU-Meter zeigt sofort die angewandte Unterdrückungsmenge an, praktisch, um den besten Kompromiss zwischen Sanftheit und Natürlichkeit zu finden.
Der Split-Modus wendet die Reduktion nur auf die hohen Frequenzen an, für eine maximale Unterdrückung der Zischlaute, wenn diese das Signal dominieren. Der Wideband-Modus, sanfter, wirkt auf das gesamte Spektrum und ist oft sehr effektiv bei Stimmen, insbesondere wenn ein transparentes Ergebnis gewünscht wird. Dieser Modus vermeidet außerdem die Auswirkungen eines Crossovers im Signalweg, um die Kohärenz des Timbres zu bewahren.
Um die Zielgenauigkeit schnell zu verfeinern, erlaubt DeEsser, das Entfernte vorzuhören: eine sehr effektive Methode, um sicherzustellen, dass die "s"- und "sch"-Laute erfasst werden, ohne nützliche Brillanz zu entfernen. Presets sind für männliche und weibliche Stimmen sowie für breitere Kontexte wie komplette Mixe enthalten, um mit einer passenden Basis zu starten und Zeit in der Session zu sparen.