Garantía de satisfacción de 30 días o reembolso
Atención al cliente : 911 231 473
 es
es 









Software completo
Waves DeEsser es un plugin de procesamiento dinámico diseñado para atenuar las sibilancias y la agresividad de las frecuencias altas en una señal de audio. Está dirigido principalmente a producciones vocales (canto, voz en off, podcast, audiolibro, narración) donde se busca mejorar la inteligibilidad sin que las consonantes "s" y "ch" se vuelvan demasiado prominentes tras la ecualización o compresión. Gracias a su acción progresiva, también es muy adecuado para suavizar fuentes ricas en transitorios como platillos, loops de batería, o para "alisar" el brillo a veces duro de ciertos sintetizadores y procesamientos digitales.
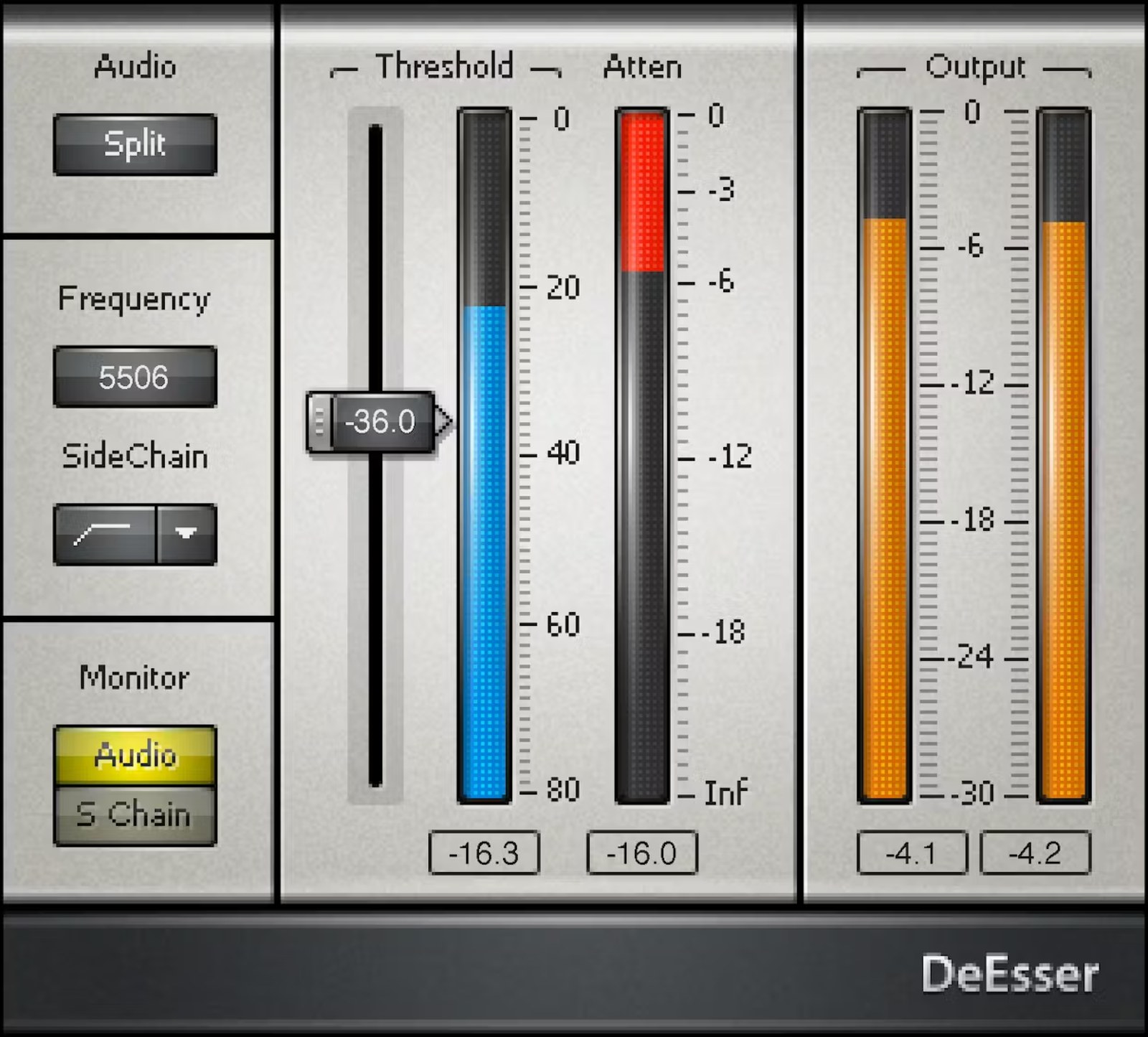
Para adaptarse a voces y grabaciones muy diferentes, DeEsser ofrece dos modos de sidechain. El modo Highpass trabaja en una zona amplia para reducir las sibilancias más invasivas en un espectro extendido, ideal cuando las "eses" varían mucho según las palabras. El modo Bandpass, por el contrario, permite bloquear una zona problemática más estrecha para apuntar con precisión a la frecuencia que desencadena la agresividad.
El flujo de trabajo es intencionalmente directo: se selecciona la zona a tratar (de 2 kHz a 16 kHz), luego se ajusta el Threshold para dosificar la reducción. El plugin se basa en una lógica de compresión con knee duro, lo que facilita obtener un resultado limpio y controlable. El vu-metro de atenuación permite visualizar inmediatamente la cantidad de supresión aplicada, práctico para encontrar el mejor equilibrio entre suavidad y naturalidad.
El modo Split aplica la reducción solo en las frecuencias altas, para un rechazo máximo de las sibilancias cuando estas dominan la señal. El modo Wideband, más suave, actúa sobre todo el espectro y suele ser muy eficaz en voces, especialmente cuando se busca un resultado transparente. Este modo también evita el impacto de un crossover en la ruta de procesamiento, para preservar la coherencia del timbre.
Para afinar rápidamente el enfoque, DeEsser permite pre-escuchar lo que se suprime: un método muy eficaz para confirmar que se capturan bien las "s" y "ch", sin eliminar brillo útil. Se incluyen presets para voz masculina y femenina, así como para contextos más amplios como mezclas completas, para partir de una base pertinente y ahorrar tiempo en sesión.